Java集合原理和底层数据结构总结
先放一张集合的层级图
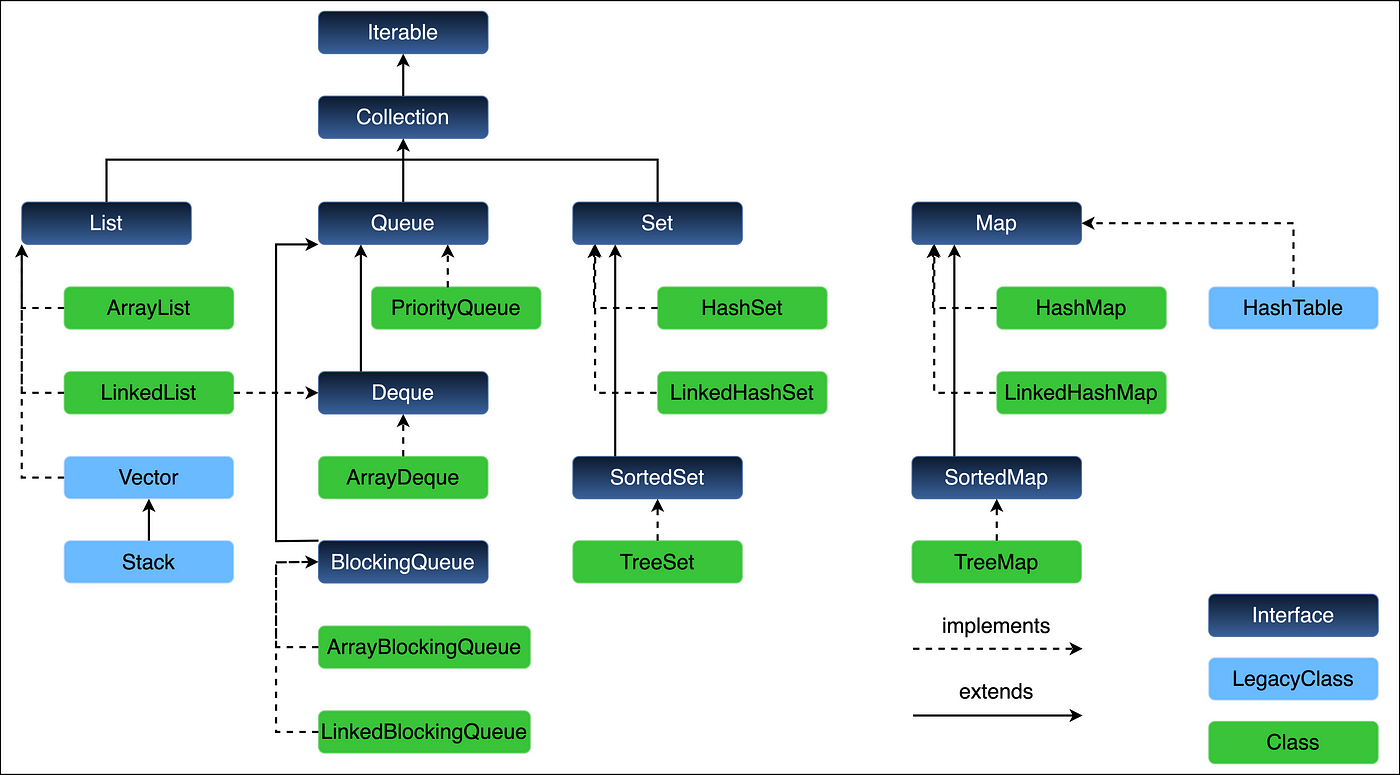
List
List的特点是顺序性,可重复性。
ArrayList
允许任何元素包括null。和Vector相比不是线程安全的。在必要时可以用Collections.synchronizedList()来将ArrayList转换成线程安全的List
1 | List list = Collections.synchronizedList(new ArrayList()); |
底层维护了一个Object数组用来存储元素。
1 | transient Object[] elementData; |
定义了一个grow()方法,当调用一系列重载的add方法时,会根据是否到达capacity来调用grow()以保证ArrayList的容量满足需求。
PriorityQueue
PriorityQueue通过维护了一个小顶堆来保证首元素是所有元素中最小的元素,最小取决于元素实现的Comparator或者Comparable。它也提供了一个构造函数以便传入自定义的Comparator来决定排序的顺序。
1 | public PriorityQueue(Comparator<? super E> comparator) |
1 | transient Object[] queue; |
这里的modCount是一个用来记录restructure(添加,删除或改变集合中元素的排列顺序)次数的变量,当创建了iterator之后如果modCount发生了变化就会抛出ConcurrentModificationException异常。
ProrityQueue不允许插入null值。
插入,删除头部元素操作的时间复杂度为O(logn)。查找和删除指定元素的时间复杂度为O(n)。
插入元素的操作
- 超出
capacity,需要无论在什么位置插入,都需要O(n)将原数组复制到更大的数组中,再用O(1)进行插入操作,所以时间复杂度为O(n)。 - 没有超出
capacity- 在尾部插入
O(1) - 在其他位置
O(n)
- 在尾部插入
删除元素的操作
- 删除尾部元素
O(1) - 删除其他位置
O(n)
RandomAccess
ArrayList实现了RandomAccess接口,表示可以随机访问,即可以根据下标访问元素,因为底层是一个数组,数组天生具备随机访问的能力。
LinkedList
LinkedList在底层维护了一个双向链表来存储数据
1 | transient int size = 0; |
1 | private static class Node<E> { |
每一个LinkedList包含两个指针分别指向链表的头节点和末节点。
RandomAccess
显然,LinkedList并不支持随机访问,因为链表在查找元素时需要线性遍历整个链表,时间复杂度为O(n),不能做到像数组那样O(1)的直接访问。
Methods
对于插入和删除操作主要有两个系列
- add and remove
addFirst(),addLast()removeFirst(),removeLast()
- offer and poll
offerFirst(),offerLast()pollFirst(),pollLast()
主要的区别的在于1在remove的时候如果list为空会抛出异常而2的poll只会返回false。
其实当调用2系列方法的时候实际上也会调用1的对应方法,如
1 | public boolean offerLast(E e) { |
在链表头和尾插入或删除的时间复杂度为O(1)。在其他位置插入或删除的时间复杂度均为O(n)。
Queue
队列的最大特点是实现了FIFO(First In First Out)的数据结构,所以很适合在有顺序需求的场景下应用。
在Queue接口下还有一个子接口Deque,在Queue的基础上实现了双端队列的逻辑,同时可以用来模拟Stack。
可以用ArrayDeque或者LinkedList来实现Queue接口,但相比之下ArrayDeque不允许null值。值得一提的是当用来模拟Stack的时候使用ArrayDeque比Stack效率高,同时在用作队列时效率比LinkedList高。
ArrayDeque
ArrayDeque的底层维护着一个循环数组,这就是为什么他可以被用作双端队列。除了remove一系列的方法和contains,其他的方法都保持在常数级别的复杂度。
1 | transient Object[] elements; |
在执行添加操作的时候,只需要移动头指针或者尾指针即可。
Set
Set主要应用场景是去重。
HashSet
HashSet的底层其实维护着一个HashMap,只不过插入HashSet中的所有元素的Value全部都被设置为了一个Object
1 | private static final Object PRESENT = new Object(); |
当执行add()操作时,就会讲value设置为上面这个`PRESENT
1 | public boolean add(E e) { |
TreeSet
TreeSet底层维护的是一个红黑树,可以实现插入元素的自动排序。
Comparator and Comparable
自动排序依赖的是元素实现的Comparator或者Comparable接口,在构造方法中也可以将实现的Comparator接口作为参数传入,并按照实现的接口的方式对TreeSet内的元素进行排序。
1 | TreeSet(Comparator<? super E> comparator) |
假如TreeSet的元素必须实现Comparator或者Comparable接口,或者在构造方法中传入一个Comparator的实现类。否则在向TreeSet中插入元素的时候会发生ClassCastException异常。
当在构造方法中传入Comparator的时候会覆盖原有方法中的Comparable或Comparator。
下面是一个例子
1 | // 自定义Person类,实现了Comparable接口,先比较age再比较name |
1 | // 测试 |
1 | Output: |
1 | // 重写Comparator, 先按照相反的顺序比较age,再比较name |
1 | Output: |
Map
Map主要是存放类似<key, value>这样的键值对的数据结构。
HashMap的底层数据结构在Java8之前采用的是数组+链表的形式,数组的每一个元素即为哈希桶,同一个桶中存在多个元素时(发生哈希冲突)将同一个桶中的元素存储在链表中。
Java8之后对链表进行了改进,当链表长度超过阈值(默认值8)之后链表会被转化成红黑树,从而提高查询效率(从O(n)提升至O(logn))
HashMap
null值的处理
HashMap的Key和Value都可以是null(Key只可以有一个null,Value可以有多个null)。
线程安全性
HashMap是Map接口的实现类之一。和HashTable相比HashMap不是线程安全的,并且为了避免多线程问题带来的问题,当遇到多线程问题时,应当使用Collections.synchronizedMap把HashMap包装成线程安全的Map或者直接使用ConcurrentHashMap
1 | Map m = Collections.synchronizedMap(new HashMap(...)); |
下面是一个存在线程安全问题的例子
1 | Map<String, Integer> map = new HashMap<>(); |
1 | Output: |
因为在单独使用HashMap的情况下,不能保证线程安全。
使用Collections.synchronizedMap包装HashMap之后
1 | Map<String, Integer> map = Collections.synchronizedMap(new HashMap<>()); |
1 | output: |
总结:Collections.synchronizedMap包装之后的HashMap可以保证线程安全,即在同一时间内只能有一个对map的操作生效,不会发生冲突,或者说所有对map的操作都是同步的,有严格的先后顺序的。
遍历顺序可变
此外,HashMap不能保证遍历时的顺序不变(因为Key的存储取决于哈希值,当进行插入,删除或者Rehashing等操作的时候会改变Key之间的相对位置,从而改变遍历的顺序)。
initial capacity 和 load factor
HashMap有两个参数initial capacity和load factor,可以在构造函数中进行设置。
1 | HashMap() // 默认initial capacity为16, load factor为0.75 |
Initial capacity是哈希桶的初始数量。
load factor是负载因子,用来衡量哈希表的密度。
$$
Load \ Factor(\alpha) = \frac{Number \ of \ Elements}{Capacity \ of \ Hash \ Table}
$$
当负载因子较小时说明哈希表比较稀疏,发生哈希碰撞的可能较小,但需要更多的内存空间。相反,负载因子过大时说明哈希表过于稠密,很容易发生哈希碰撞,降低了查找,插入和删除的效率,但减少了内存消耗。
在HashMap中,load factor的默认值为0.75,意味着当HashMap的元素达到当前capacity的75%时HashMap就会自动进行Rehashing并且自动扩容为原来的两倍。
HashMap的基本操作(get(), put()等)的时间复杂度都是O(1),但这依赖于对两个基本参数initial capacity和load factor的合理设置。
Fieids
HashMap的底层是一个Node<K, V>类型的数组,这个数组其实就是哈希桶,每一个桶可以存放一个Node,实际上就是链表(或红黑树)
1 | transient Node<K,V>[] table; |
Node是HashMap的一个内部类
1 | static class Node<K,V> implements Map.Entry<K,V> { |
LinkedHashMap
LinkedHashMap是HashMap的子类,在HashMap的基础上添加了双向链表来保证遍历的顺序。当在需要保证遍历顺序和插入顺序相同的场景下LinkedHashMap非常合适。
accessOrder
LinkedHashMap和HashMap相比多了一个特别的构造方法
1 | LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) |
新参数accessOrder是一个布尔值,默认为false,表示按照插入顺序进行遍历,为true时表示按照访问顺序排序(访问过的元素排在末尾)。可见当按照访问顺序遍历时非常适合用来模拟LRU缓存。
1 | import java.util.LinkedHashMap; |
removeEldestEntry会在put方法被调用时被执行,如果返回值为true就会移除首个元素。
下面是测试代码
1 | LRUCache<Integer, Integer> cache = new LRUCache<>(5); |
1 | Output: |
此外,和HashMap不同的是LinkedHashMap在遍历的时候不受capacity的影响,因为LinkedHashMap按照双向链表遍历而不是遍历哈希桶。
同样的,LinkedHashMap也不是线性安全的,在多线程并发场景下需要使用Collections.synchronizedMap()进行包装。








